
HOME»基本情報技術者平成29年秋期»午後問12
基本情報技術者平成29年秋期 午後問12
⇄問題文と設問を画面2分割で開く⇱問題PDF⇱アセンブラ言語の仕様問12 ソフトウェア開発(アセンブラ)
次のアセンブラプログラムの説明及びプログラムを読んで,設問1~4に答えよ。
〔プログラム1の説明〕
連続する2語から成るビット列αの中から,別のビット列βと一致する部分ビット列を検索する副プログラム BSRH である。部分ビット列の検索の概要を,図1に示す。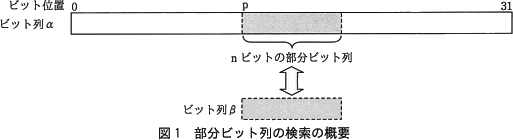
〔プログラム1の説明〕
連続する2語から成るビット列αの中から,別のビット列βと一致する部分ビット列を検索する副プログラム BSRH である。部分ビット列の検索の概要を,図1に示す。
- 主プログラムは,αが格納されている領域の先頭アドレスを GR1 に,βを GR2 に,βの長さn(1≦n≦16)を GR3 に設定して副プログラム BSRH を呼ぶ。βは GR2 に左詰めで設定し,残りのビットには0を設定する。
- 副プログラム BSRH は,αの先頭(ビット位置0)からβと照合し,一致する部分ビット列がある場合は最初に一致する部分ビット列の先頭のビット位置 p を,一致する部分ビット列がない場合は-1を,GR0 に設定して主プログラムに戻る。
- 副プログラム BSRH から戻るとき,汎用レジスタ GR1~GR7 の内容は元に戻す。
設問1
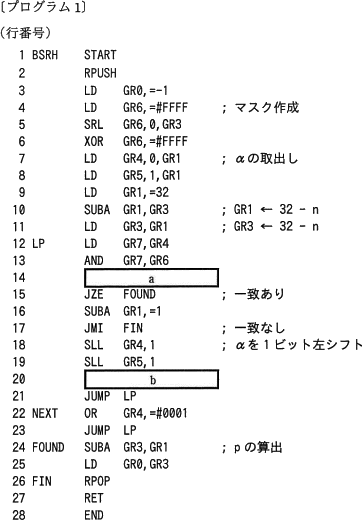
プログラム1中の に入れる正しい答えを,解答群の中から選べ。
a に関する解答群
- AND GR7,GR2
- OR GR7,GR2
- SLL GR7,0,GR2
- SRL GR7,0,GR2
- XOR GR7,GR2
b に関する解答群
- JMI FOUND
- JMI NEXT
- JOV FOUND
- JOV NEXT
- JPL FOUND
- JPL NEXT
解答選択欄 :
- a:
- b:
解答 :
- a=オ
- b=エ
解説 :
まず〔プログラム1〕の先頭からaに至るまでトレースしていきます。
選択肢を見ると、GR2 と GR7 で何かを行うことがわかります。GR2 は置換対象のビット列が格納されており、続く15行目のコメントに「一致あり」とあることから、GR7 のビット列が置換対象のビット列を一致するかどうかを確認するための処理を入れなければなりません。
2つのビット列が完全一致する場合には、XOR演算を使うと結果が全て0になるのでこれを利用してビット列の一致を判定できます。次行がJZE命令でラベルFOUNDに分岐させているのは、GR7 が0のとき置換対象のビット列が見つかったと判断できるためです。
仮に、置換対象ビット列が 10101、αの先頭も 10101 だったとすると、次のようになります。後述しますが、αを左にずらしていったときも同じように判定します。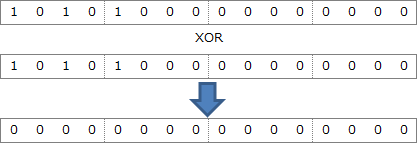 ∴a=オ:XOR GR7,GR2
∴a=オ:XOR GR7,GR2
GR4 と GR5 を左に1ビットシフトした後に行う分岐命令です。やや消去法的になりますが、ここまでラベルNEXTに分岐させる命令がなく、ここでラベルNEXTに飛ばさないと次行でループの先頭(ラベルLP)に戻ることになるので、[b]にはラベルNEXTに分岐させる命令が入るとわかります。もしそうでなければ、ラベルNEXT以降の2行が実行される機会がなくなってしまうからです。
このプログラムでは、常に GR4 の先頭nビットと GR2 との比較で置換対象のビット列か否かを確認していて、一致しなかった場合にはビット列α全体を左に1ビットシフトシフトさせて、再び GR2 と照合することを繰り返します。ここで、ビット列αはひとまとまりのビット列として扱う必要があるので、GR5 を左にシフトさせたときにあふれ出たビットを GR4 の最下位ビットにする処理が必要となります。 SLLやSRLなどのシフト命令を実行すると、最後にあふれ出たビットがOFに設定されるので、[b]実行時のOFには GR5 からあふれ出たビットが入っています。1ビット左シフト後の GR4 の最下位ビットには0が格納されているので、OFが0のときには特に処理をする必要はありませんが、OFが1のときには GR4 の最下位ビットに1を格納し、GR4 と GR5 を繋ぐ処理が必要です。この処理を行っているのがラベルNEXTの行です。
SLLやSRLなどのシフト命令を実行すると、最後にあふれ出たビットがOFに設定されるので、[b]実行時のOFには GR5 からあふれ出たビットが入っています。1ビット左シフト後の GR4 の最下位ビットには0が格納されているので、OFが0のときには特に処理をする必要はありませんが、OFが1のときには GR4 の最下位ビットに1を格納し、GR4 と GR5 を繋ぐ処理が必要です。この処理を行っているのがラベルNEXTの行です。
ラベルNEXTに分岐させるのは、GR5 からあふれ出たビットが1、すなわちOFが1のときなので、JOV命令でラベルNEXTに分岐させる「エ」が適切です。
∴b=エ:JOV NEXT
- 4~6行目
- GR6 に先頭からn個が1であるビットマスクを作成
例えばn=5ならば、次の手順でビットマスクとなる
- 7~8行目
- ビット列αの1語目を GR4 に、2語目を GR5 に格納
- 12~13行目
- GR7 に1語目のビット列を格納し、先頭からnビットを GR6(ビットマスク)とのAND演算で取り出す
選択肢を見ると、GR2 と GR7 で何かを行うことがわかります。GR2 は置換対象のビット列が格納されており、続く15行目のコメントに「一致あり」とあることから、GR7 のビット列が置換対象のビット列を一致するかどうかを確認するための処理を入れなければなりません。
2つのビット列が完全一致する場合には、XOR演算を使うと結果が全て0になるのでこれを利用してビット列の一致を判定できます。次行がJZE命令でラベルFOUNDに分岐させているのは、GR7 が0のとき置換対象のビット列が見つかったと判断できるためです。
仮に、置換対象ビット列が 10101、αの先頭も 10101 だったとすると、次のようになります。後述しますが、αを左にずらしていったときも同じように判定します。
- AND演算では GR7 が変わらないので誤りです。
- GR2 の値は先頭nビットが1となっており、数値換算すると相当に大きな数です。この値をシフトに使うのは適切ではありません。
- 「イ」と同様の理由で誤りです。
- OR演算では GR7 の先頭nビットがすべて1になる(GR6と同じになる)ので誤りです。
- 正しい。
GR4 と GR5 を左に1ビットシフトした後に行う分岐命令です。やや消去法的になりますが、ここまでラベルNEXTに分岐させる命令がなく、ここでラベルNEXTに飛ばさないと次行でループの先頭(ラベルLP)に戻ることになるので、[b]にはラベルNEXTに分岐させる命令が入るとわかります。もしそうでなければ、ラベルNEXT以降の2行が実行される機会がなくなってしまうからです。
このプログラムでは、常に GR4 の先頭nビットと GR2 との比較で置換対象のビット列か否かを確認していて、一致しなかった場合にはビット列α全体を左に1ビットシフトシフトさせて、再び GR2 と照合することを繰り返します。ここで、ビット列αはひとまとまりのビット列として扱う必要があるので、GR5 を左にシフトさせたときにあふれ出たビットを GR4 の最下位ビットにする処理が必要となります。
ラベルNEXTに分岐させるのは、GR5 からあふれ出たビットが1、すなわちOFが1のときなので、JOV命令でラベルNEXTに分岐させる「エ」が適切です。
∴b=エ:JOV NEXT
設問2
プログラム1の行番号4~6を,次の2命令で置き換えても,GR6 には同じ値が得られる。 に入れる正しい答えを,解答群の中から選べ。
LD GR6,=#8000
LD GR6,=#8000
解答群
- SLL GR6,-1,GR3
- SLL GR6,0,GR3
- SRA GR6,-1,GR3
- SRA GR6,0,GR3
- SRL GR6,-1,GR3
- SRL GR6,0,GR3
解答選択欄 :
解答 :
- ウ
解説 :
前述の通り4~6行目の処理は、先頭からnビットが1のビットマスクを作成する処理です。GR6 に#8000を代入すると、先頭ビットだけが1のビット列となりますから、算術シフトを用いて右に(n-1)ビットシフトすれば、先頭からnビットが1のビット列を作ることが可能です。仮にnが5ならば、右に4ビット算術シフトさせることになります。 算術右シフトを行う命令は SRA で、βの長さnは GR3 に格納されています。したがって GR6 を GR3 の値よりも1小さい数だけ右算術シフトさせる「SRA GR6,-1,GR3」が適切です。
算術右シフトを行う命令は SRA で、βの長さnは GR3 に格納されています。したがって GR6 を GR3 の値よりも1小さい数だけ右算術シフトさせる「SRA GR6,-1,GR3」が適切です。
∴ウ:SRA GR6,-1,GR3
※算術シフトでは、符号ビット(最上位1ビット)を除いた15ビットをシフトします。算術左シフトでは空いたビットに0が入りますが、算術右シフトでは空いたビットには符号ビットと同じビットが入ります。一方、論理シフトは16ビット全部をシフトし、空いたビットには0が入ります。
∴ウ:SRA GR6,-1,GR3
※算術シフトでは、符号ビット(最上位1ビット)を除いた15ビットをシフトします。算術左シフトでは空いたビットに0が入りますが、算術右シフトでは空いたビットには符号ビットと同じビットが入ります。一方、論理シフトは16ビット全部をシフトし、空いたビットには0が入ります。
設問3
αの先頭からβと照合し,最初に一致する部分ビット列を,βと同じ長さの別のビット列γで置き換える副プログラム BREP を,副プログラム BSRH を使用して作成した。γは GR4 に左詰めで設定し,残りのビットには0を設定する。それ以外の BREP の呼出しに関する仕様は,プログラム1の説明中の BSRH を BREP に読み替えて適用する。プログラム2中の に入れる正しい答えを,解答群の中から選べ。
c に関する解答群
- ADDL GR2,GR7
- LD GR2,=0
- LD GR2,=16
- LD GR2,=32
- SUBA GR2,GR7
d に関する解答群
- AND GR2,GR4
- OR GR2,GR4
- SLL GR2,0,GR4
- SRL GR2,0,GR4
- XOR GR2,=#FFFF
解答選択欄 :
- c:
- d:
解答 :
- c=イ
- d=イ
解説 :
cがあるラベルONL2に分岐するまでを簡単にトレースします。
ラベルONL2に分岐した時点で、GR2 には p が、GR3 には (16-p) が格納されています。次行でそのまま GR2 - GR3 を行っても「p-(1-p)=16」になるだけで、コメント部にある (p-16) を GR2 に求めることはできません。よって[c]には、次行の命令が適切に動作するように GR2 の値を調整する処理が入ります。
GR3 が (16-p) なので、単純に符号を逆にすれば (p-16) になります。[c]で GR2 に0を格納しておけば、次行で GR2 - GR3 が「0-(16-p)=p-16」となり、適切な値が GR2 に求まります。よって「イ」が適切です。
ここでは、先頭位置が2語目にある場合に先頭位置(p)に対応する2語目のビット位置を求めています。仮に先頭位置が20ならば、2語目の4ビット目が置換対象ビット列の先頭ですから、GR2 には4が格納されることになります。
∴c=イ:LD GR2,=0
〔dについて〕
ラベルS1に分岐した時点で GR4 には置換するビット列(γ)が、GR6 にはビットマスクが格納されています。その後、dに至るまで次の処理が行われます。
∴d=イ:OR GR2,GR4
- 2~4行目
- 副プログラム BSRH を呼ぶと GR0 に置換対象のビット列の先頭位置(p)が格納されているので、それを GR2 にコピーします。BSRH から返された先頭位置が-1なら、ビット列αに置換対象のビット列と一致する部分はないのでJMI命令でプログラムを終了します。
- 6~8行目
- 副プログラム BSRH と同様の手順でビットマスクを生成し GR6 に格納します。
- 9~11行目
- GR7 に置換対象ビット列の長さ(n)をコピーした後、GR3 に (16-p) を求めています。
- 12~13行目
- 置換対象のビット列の先頭位置が1語目にあれば、GR3(=p)は0~15、2語目にあれば16~となります。つまり、(16-p) が0以下であれば先頭位置が2語目にあることになります。よって、JMI命令とJZE命令を組み合わせて、先頭位置が2語目にあるときの処理を行うラベルONL2に分岐させています。
ラベルONL2に分岐した時点で、GR2 には p が、GR3 には (16-p) が格納されています。次行でそのまま GR2 - GR3 を行っても「p-(1-p)=16」になるだけで、コメント部にある (p-16) を GR2 に求めることはできません。よって[c]には、次行の命令が適切に動作するように GR2 の値を調整する処理が入ります。
GR3 が (16-p) なので、単純に符号を逆にすれば (p-16) になります。[c]で GR2 に0を格納しておけば、次行で GR2 - GR3 が「0-(16-p)=p-16」となり、適切な値が GR2 に求まります。よって「イ」が適切です。
ここでは、先頭位置が2語目にある場合に先頭位置(p)に対応する2語目のビット位置を求めています。仮に先頭位置が20ならば、2語目の4ビット目が置換対象ビット列の先頭ですから、GR2 には4が格納されることになります。
∴c=イ:LD GR2,=0
〔dについて〕
ラベルS1に分岐した時点で GR4 には置換するビット列(γ)が、GR6 にはビットマスクが格納されています。その後、dに至るまで次の処理が行われます。
- 35~36行目
- γとビットマスクを右シフトして操作対象語の置換対象位置に移動させています。
- 37\行目
- GR2 に操作対象語をコピーしています。
- 38~39行目
- ビットマスクを反転させたビット列と GR2 のAND演算を行っています。これにより、操作対象語のうち置換対象範囲以外のビットを取り出した GR2 に格納されます。
仮に先頭位置が5、nが7ならば、次のように処理されます。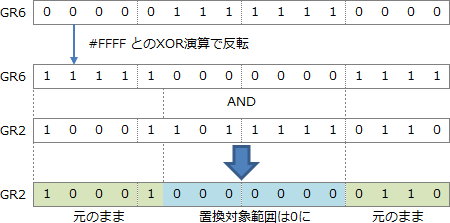
∴d=イ:OR GR2,GR4
設問4
次の設定で,プログラム2を実行したとき,行番号23の命令実行直後の GR6 に格納されている値として正しい答えを,解答群の中から選べ。
α:1語目 #FFF3
2語目 #7FFF
β:(11011)2
n:5
γ:(11110)2
α:1語目 #FFF3
2語目 #7FFF
β:(11011)2
n:5
γ:(11110)2
解答群
- #0003
- #0007
- #8000
- #C000
- #E000
- #F000
解答選択欄 :
解答 :
- オ
解説 :
まず、ビット列αの中で置換対象のビット列(11011)がどこに位置するのかを確認すると、最上位ビットが0番目なので、置換対象ビット列の先頭位置 p は14になることがわかります。 行番号12~13の分岐命令の時点で、GR3 には「16-14=2」、n=5 より GR6 には「1111 1000 0000 0000」が格納されています。このケースでは置換対象が2語にまたがっている(16-p<n)ので16行目のJMI命令により、ラベルNEXTに分岐します。
行番号12~13の分岐命令の時点で、GR3 には「16-14=2」、n=5 より GR6 には「1111 1000 0000 0000」が格納されています。このケースでは置換対象が2語にまたがっている(16-p<n)ので16行目のJMI命令により、ラベルNEXTに分岐します。
ラベルNEXTの直後2行では、GR4 の値を GR5 に、GR6 の値を GR7 にそれぞれ退避させています。その後 S1 が呼ばれますが、S1 の中では GR5 と GR7 の値が変更されていないので、S1 から戻った後の20~21行目のLD命令では、GR4 と GR6 にそれぞれ S1 が呼ばれる前の値が入ることになります。23行目のSLL命令では、GR6 に格納されている「1111 1000 0000 0000」を、GR3(=2)だけ左論理シフトするので、GR6 の値は「1110 0000 0000 0000」となります。これを16進数で表すと「#E000」です。 ∴オ:#E000
∴オ:#E000
ラベルNEXTの直後2行では、GR4 の値を GR5 に、GR6 の値を GR7 にそれぞれ退避させています。その後 S1 が呼ばれますが、S1 の中では GR5 と GR7 の値が変更されていないので、S1 から戻った後の20~21行目のLD命令では、GR4 と GR6 にそれぞれ S1 が呼ばれる前の値が入ることになります。23行目のSLL命令では、GR6 に格納されている「1111 1000 0000 0000」を、GR3(=2)だけ左論理シフトするので、GR6 の値は「1110 0000 0000 0000」となります。これを16進数で表すと「#E000」です。