大原本問題集 66
まきさん
(No.1)
以下のマージソートのプログラムが分からなさ過ぎて涙が止まりません
(1)~(4)まで答えを入れてプログラムを完成させてみました
問題文の根拠の部分探したり、解説を読んでも全く分からないです。
改めて基礎に戻っているのに、このプログラムの構造や動きがどうなっているのか分かりません。よくあるマージソートの図は分かるのですが。プログラムにすると途端に読めなくなります。いままで基礎からやり直してきたのになんだか出来ない自分を責めてしまいそうです。決して考えを放棄しているわけではありません。何故この答となるのでしょうか
分かる方解説をお願い致します。
大域:整数型:hv←10000
○mergesort(整数型の配列:a,l,r)
整数型 m
if(l<r)
m←(l+r)/2
mergesort(a,l,m) //前半再分割//
mergesort(a,m+1,r)//後半再分割// (1)
merge(a,l,m,r) //前半後半併合//
endif
○merge(整数型の配列:a,l,r)
整数型:i,j,k,n1,n2
整数型の配列:ll,rr
n1←m-l+1 (2) //前半の要素数//
n2←r-m //後半の要素数//
i←l
for(k,1~n1,1) //前半を配列llに転記//
ll[k]←a[i]
i←i+1
endfor
ll[n1+1]←hv(3)
j←m+1(4)
for(k,1~n2,1)
rr[k]←a[j] //後半を配列llに転記//
j←j+1
endfor
rr[n2+1]←hv(3)
i←1
j←1
for(k,l~r,1)
if(ll[i]<=rr[j]) //前半と後半から//
a[k]←ll[i] //要素の小さい順に//
i←i+1 //取り出し、配列aに格納//
else
a[k]←rr[j]
j←j+1
endif
endfor
(1)~(4)まで答えを入れてプログラムを完成させてみました
問題文の根拠の部分探したり、解説を読んでも全く分からないです。
改めて基礎に戻っているのに、このプログラムの構造や動きがどうなっているのか分かりません。よくあるマージソートの図は分かるのですが。プログラムにすると途端に読めなくなります。いままで基礎からやり直してきたのになんだか出来ない自分を責めてしまいそうです。決して考えを放棄しているわけではありません。何故この答となるのでしょうか
分かる方解説をお願い致します。
大域:整数型:hv←10000
○mergesort(整数型の配列:a,l,r)
整数型 m
if(l<r)
m←(l+r)/2
mergesort(a,l,m) //前半再分割//
mergesort(a,m+1,r)//後半再分割// (1)
merge(a,l,m,r) //前半後半併合//
endif
○merge(整数型の配列:a,l,r)
整数型:i,j,k,n1,n2
整数型の配列:ll,rr
n1←m-l+1 (2) //前半の要素数//
n2←r-m //後半の要素数//
i←l
for(k,1~n1,1) //前半を配列llに転記//
ll[k]←a[i]
i←i+1
endfor
ll[n1+1]←hv(3)
j←m+1(4)
for(k,1~n2,1)
rr[k]←a[j] //後半を配列llに転記//
j←j+1
endfor
rr[n2+1]←hv(3)
i←1
j←1
for(k,l~r,1)
if(ll[i]<=rr[j]) //前半と後半から//
a[k]←ll[i] //要素の小さい順に//
i←i+1 //取り出し、配列aに格納//
else
a[k]←rr[j]
j←j+1
endif
endfor
2024.04.01 22:45
jjon-comさん
★FE プラチナマイスター
(No.2)
とりあえず,以下の変数名が次を意味していることは分かっているのでしたっけ。
変数名 l …Left 対象配列の「左端」を指す添字
変数名 r …Right 対象配列の「左端」を指す添字
変数名 m …Middle 対象配列の「真ん中」を指す添字
変数名 l …Left 対象配列の「左端」を指す添字
変数名 r …Right 対象配列の「左端」を指す添字
変数名 m …Middle 対象配列の「真ん中」を指す添字
2024.04.02 16:28
jjon-comさん
★FE プラチナマイスター
(No.3)
次に,
とのことなので,
基本情報 平成22年 春期 午後 問8
https://www.fe-siken.com/kakomon/22_haru/pm08.html
の解説に掲載された図を例にします。
配列要素をどう整列するかは「とりあえず無視して」
(図中の赤字の④⑤⑨⑩⑪⑫はとりあえず無視して)
指定さえすれば整列結果が得られるという仮定で話をするならば。
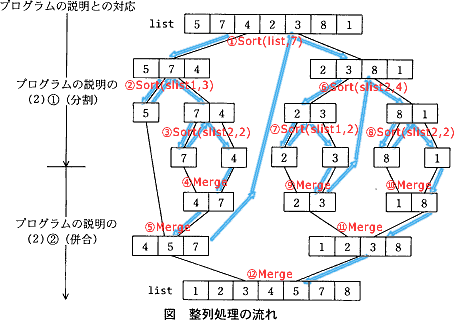
に適用したものが,
次の説明に対応することは分かるのでしたっけ。
①a[5, 7, 4, 2, 3, 8, 1]の整列結果を得たいなら
a[5, 7, 4] を対象配列とした整列結果と
a[2, 3, 8, 1]を対象配列とした整列結果とを
併合(merge)すればよい
②a[5, 7, 4]の整列結果を得たいなら
a[5] を対象配列とした整列結果と
a[7, 4]を対象配列とした整列結果とを
併合(merge)すればよい
③a[7, 4]の整列結果を得たいなら
a[7]を対象配列とした整列結果と
a[4]を対象配列とした整列結果とを
併合(merge)すればよい
⑥a[2, 3, 8, 1]の整列結果を得たいなら
a[2, 3]を対象配列とした整列結果と
a[8, 1]を対象配列とした整列結果とを
併合(merge)すればよい
⑦a[2, 3]の整列結果を得たいなら
a[2]を対象配列とした整列結果と
a[3]を対象配列とした整列結果とを
併合(merge)すればよい
⑧a[8, 1]の整列結果を得たいなら
a[8]を対象配列とした整列結果と
a[1]を対象配列とした整列結果とを
併合(merge)すればよい
> よくあるマージソートの図は分かるのですが
とのことなので,
基本情報 平成22年 春期 午後 問8
https://www.fe-siken.com/kakomon/22_haru/pm08.html
の解説に掲載された図を例にします。
配列要素をどう整列するかは「とりあえず無視して」
(図中の赤字の④⑤⑨⑩⑪⑫はとりあえず無視して)
指定さえすれば整列結果が得られるという仮定で話をするならば。
○mergesort(整数型の配列:a,l,r)
整数型 m
if (l < r)
m←(l+r)/2
mergesort(a,l,m) //前半再分割//
mergesort(a,m+1,r)//後半再分割// (1)
merge(a,l,m,r) //前半後半併合//
endif
を整数型 m
if (l < r)
m←(l+r)/2
mergesort(a,l,m) //前半再分割//
mergesort(a,m+1,r)//後半再分割// (1)
merge(a,l,m,r) //前半後半併合//
endif
に適用したものが,
次の説明に対応することは分かるのでしたっけ。
①a[5, 7, 4, 2, 3, 8, 1]の整列結果を得たいなら
a[5, 7, 4] を対象配列とした整列結果と
a[2, 3, 8, 1]を対象配列とした整列結果とを
併合(merge)すればよい
②a[5, 7, 4]の整列結果を得たいなら
a[5] を対象配列とした整列結果と
a[7, 4]を対象配列とした整列結果とを
併合(merge)すればよい
③a[7, 4]の整列結果を得たいなら
a[7]を対象配列とした整列結果と
a[4]を対象配列とした整列結果とを
併合(merge)すればよい
⑥a[2, 3, 8, 1]の整列結果を得たいなら
a[2, 3]を対象配列とした整列結果と
a[8, 1]を対象配列とした整列結果とを
併合(merge)すればよい
⑦a[2, 3]の整列結果を得たいなら
a[2]を対象配列とした整列結果と
a[3]を対象配列とした整列結果とを
併合(merge)すればよい
⑧a[8, 1]の整列結果を得たいなら
a[8]を対象配列とした整列結果と
a[1]を対象配列とした整列結果とを
併合(merge)すればよい
2024.04.02 16:28
まきさん
(No.4)
>jjon-comさん
ご丁寧な解説をありがとうございます。
no2とno3の解説されたイメージは出来ています。
ただ擬似言語のプログラムになった時になにこれってなってしまって、
mergeのプログラムはなにやっているのかと思って・・・すみません。
これも潰してゆくしかないんですよね
2024.04.02 17:30
jjon-comさん
★FE プラチナマイスター
(No.5)
> no2とno3の解説されたイメージは出来ています。
であるなら,それを確認したいです。
①a[5, 7, 4, 2, 3, 8, 1]の整列結果を得たい
ときに
○mergesort(整数型の配列:a,整数型:l,整数型:r)
整数型 m
if (l < r)
m←(l+r)/2
mergesort(a,l,m) //前半再分割//
mergesort(a,m+1,r)//後半再分割// (1)
merge(a,l,m,r) //前半後半併合//
endif
における lの値,rの値,mの値 を3つとも挙げることができますか?整数型 m
if (l < r)
m←(l+r)/2
mergesort(a,l,m) //前半再分割//
mergesort(a,m+1,r)//後半再分割// (1)
merge(a,l,m,r) //前半後半併合//
endif
2024.04.02 17:51
まきさん
(No.6)
>jjon-comさん
>における lの値,rの値,mの値 を3つとも挙げることができますか?
擬似言語問題の配列で、
配列が0から始まるなら
l=0,a[0]=5,r=6 a[6]=1なので(配列番号)
m←(l+r)/2
3←(0+6)/2
m=3となります。間違えてますか?
2024.04.02 18:07
jjon-comさん
★FE プラチナマイスター
(No.7)
重要な事を言い忘れてました,失礼。
No.3のリンク先の問題は CBT以前の旧制度の出題なので,配列の添字は0始まりですが,
科目Bになった新制度の擬似言語は,配列の添字は1始まりです。
というのは正しいです。
ただ今回は,説明のために旧制度の出題のイラストを借りているだけなので,
l=1, r=7 としてこの図を読んでください。
念のため確認ですが,
m←(l+r)/2
を実行した後の m の値を挙げることができますか?
No.3のリンク先の問題は CBT以前の旧制度の出題なので,配列の添字は0始まりですが,
科目Bになった新制度の擬似言語は,配列の添字は1始まりです。
> 配列が0から始まるなら
> l=0, r=6,(配列番号)
> m=3となります。間違えてますか?
というのは正しいです。
ただ今回は,説明のために旧制度の出題のイラストを借りているだけなので,
l=1, r=7 としてこの図を読んでください。
念のため確認ですが,
m←(l+r)/2
を実行した後の m の値を挙げることができますか?
2024.04.02 18:27
まきさん
(No.8)
>念のため確認ですが,
m←(l+r)/2
を実行した後の m の値を挙げることができますか?
m←(l+r)/2
4 ←(1+7)/2 なのでm=4になります。
2024.04.02 18:44
jjon-comさん
★FE プラチナマイスター
(No.9)
> (1)~(4)まで答えを入れてプログラムを完成させてみました
> 問題文の根拠の部分探したり、解説を読んでも全く分からないです。
という「分からない」箇所を特定しようと、あえて質問を小出しにしたのですが、
ここまでの流れを理解しているのに、
> mergesort(a,l,m) //前半再分割//
> mergesort(a,m+1,r)//後半再分割// (1)
が分からないというのが解せないです。(1)はどんな点で分からないのですか?
2024.04.02 21:17
まきさん
(No.10)
(1)は問題を初めて解いてlやrの意味が何かと分からなくて解説を何回か読んで少しだけ分かりました。
たぶんマージソートを絵を見ただけの状態で分かった気になっていました。
たぶんマージソートを絵を見ただけの状態で分かった気になっていました。
2024.04.03 12:55
jjon-comさん
★FE プラチナマイスター
(No.11)
配列の要素数が奇数の場合,
No.3 の過去問題および解説図では,前半が{5, 7, 4},後半が{2, 3, 8, 1} と
後半の要素数が1つ多くなる分割をしていますが,
その大原本問題集は,前半が{5, 7, 4, 2},後半が{3, 8, 1} と
前半の要素数が1つ多くなる分割をしていることがソースコードから分かりました。
これを踏まえてソースコードにコメントを入れるとこうなります。
// No.3の図の 赤字⑫ のデータを想定して解説する
// a[] = {2, 4, 5, 7, 1, 3, 8}
// 左端の添字 l=1, 右端の添字 r=7, 真ん中の添字 m=4
○merge(整数型の配列:a, 整数型:l, 整数型:m, 整数型:r)
整数型:i,j,k,n1,n2
整数型の配列:ll,rr
// 前半a[1]~a[4]は {2, 4, 5, 7} 整列済。要素数は n1 = 4-1+1 = 4
// 後半a[5]~a[7]も {1, 3, 8} 整列済。要素数は n2 = 7-4 = 3
n1←m-l+1 (2) //前半の要素数
n2←r-m //後半の要素数
// 前半a[1]~a[4] を別の配列 ll[] = {2, 4, 5, 7, HV} にコピー。
// HV は High-Value(そのデータ型に格納可能な最大値)を表す。
i←l
for(k,1~n1,1) //前半を配列llに転記//
ll[k]←a[i]
i←i+1
endfor
ll[n1+1]←hv(3)
// 後半a[5]~a[7] を別の配列 rr[] = {1, 3, 8, HV} にコピー。
// HV は High-Value(そのデータ型に格納可能な最大値)を表す。
j←m+1(4)
for(k,1~n2,1)
rr[k]←a[j] //後半を配列rrに転記//
j←j+1
endfor
rr[n2+1]←hv(3)
// ll[] = {2, 4, 5, 7, HV} と rr[] = {1, 3, 8, HV} を併合(merge)。
// ll[] または rr[] のどちらかから小さい方の値を一つずつ取り出つつ
// a[] にコピーして,a[] = {1, 2, 3, 4, 5, 7, 8} を作り出す。
i←1
j←1
for(k,l~r,1)
if(ll[i]<=rr[j]) //前半と後半から//
a[k]←ll[i] //要素の小さい順に//
i←i+1 //取り出し、配列aに格納//
else
a[k]←rr[j]
j←j+1
endif
endfor
No.3 の過去問題および解説図では,前半が{5, 7, 4},後半が{2, 3, 8, 1} と
後半の要素数が1つ多くなる分割をしていますが,
その大原本問題集は,前半が{5, 7, 4, 2},後半が{3, 8, 1} と
前半の要素数が1つ多くなる分割をしていることがソースコードから分かりました。
これを踏まえてソースコードにコメントを入れるとこうなります。
// No.3の図の 赤字⑫ のデータを想定して解説する
// a[] = {2, 4, 5, 7, 1, 3, 8}
// 左端の添字 l=1, 右端の添字 r=7, 真ん中の添字 m=4
○merge(整数型の配列:a, 整数型:l, 整数型:m, 整数型:r)
整数型:i,j,k,n1,n2
整数型の配列:ll,rr
// 前半a[1]~a[4]は {2, 4, 5, 7} 整列済。要素数は n1 = 4-1+1 = 4
// 後半a[5]~a[7]も {1, 3, 8} 整列済。要素数は n2 = 7-4 = 3
n1←m-l+1 (2) //前半の要素数
n2←r-m //後半の要素数
// 前半a[1]~a[4] を別の配列 ll[] = {2, 4, 5, 7, HV} にコピー。
// HV は High-Value(そのデータ型に格納可能な最大値)を表す。
i←l
for(k,1~n1,1) //前半を配列llに転記//
ll[k]←a[i]
i←i+1
endfor
ll[n1+1]←hv(3)
// 後半a[5]~a[7] を別の配列 rr[] = {1, 3, 8, HV} にコピー。
// HV は High-Value(そのデータ型に格納可能な最大値)を表す。
j←m+1(4)
for(k,1~n2,1)
rr[k]←a[j] //後半を配列rrに転記//
j←j+1
endfor
rr[n2+1]←hv(3)
// ll[] = {2, 4, 5, 7, HV} と rr[] = {1, 3, 8, HV} を併合(merge)。
// ll[] または rr[] のどちらかから小さい方の値を一つずつ取り出つつ
// a[] にコピーして,a[] = {1, 2, 3, 4, 5, 7, 8} を作り出す。
i←1
j←1
for(k,l~r,1)
if(ll[i]<=rr[j]) //前半と後半から//
a[k]←ll[i] //要素の小さい順に//
i←i+1 //取り出し、配列aに格納//
else
a[k]←rr[j]
j←j+1
endif
endfor
2024.04.03 15:19
まきさん
(No.12)
解説ありがとうございます。こういったことを何回もトライして理解していきます。
2024.04.04 12:24
広告
返信投稿用フォーム
スパム防止のためにスレッド作成日から40日経過したスレッドへの投稿はできません。
広告
その他のスレッド
- 【2024年4月】試験結果報告専用スレッド
 2024.04.30 18:43|
2024.04.30 18:43| 41
41 - 旧午後試験平成25年春期問8プログラミング問題 2024.04.01 21:17| 4
- かんたん予想問題集 p220問10オリジナル問題 2024.03.31 16:08| 1